Fehlerrechnung

Martina Wagner
Mathematische Methoden und Computereinsatz
1. Einleitung
Unvermeidbarkeit von Messfehlern
Jede reale Messung einer physikalischen Grösse ist mit einer Unsicherheit im Ergebnis behaftet. Dies ist eng mit der Frage verknüpft, ob es den wahren Wert X einer physikalischen Grösse, der letztendlich ja doch ermittelt werden soll, überhaupt gibt. Im allgemeinen muss diese Frage wohl verneint werden, da der wahre Wert einer stetigen Variablen nie genau bestimmt werden kann. Wir wollen für unsere Darstellung jedoch an diesem Begriff festhalten und definieren ihn als den Mittelwert einer unendlich langen Messreihe. Er kann daher im Experiment nie tatsächlich ermittelt werden, die Messung liefert stets nur einen Bestwert xBest.
Auch der Begriff des Fehlers dx sollte geklärt werden. Ein Fehler in unserem Zusammenhang ist nicht das Ergebnis eines Fehlverhaltens des Messenden, sondern es handelt sich um die prinzipiell unvermeidliche Messunsicherheit, die jeder Messung auch bei grösster Sorgfalt anhaftet. Da sich dieser Begriff jedoch eingebürgert hat, wollen wir auch an ihm festhalten.
Die Angabe eines Messergebnisses erfolgt daher stets in der Form: wahrer Wert = Bestwert ± Fehler, oderX = xBest ± dx.
Bedeutung der Fehlerabschätzung
Hinter jeder Messung steckt eine gewisse Absicht. Die Grösse des Fehlers entscheidet oft darüber, ob eine Messung ihren Zweck erfüllt oder nicht.
Viele Messungen dienen etwa dazu, die Vorhersagen einer Theorie zu überprüfen. Berühmtestes Beispiel eines Experimentes dieser Art war die Messung der Ablenkung eines Lichtstrahls, der nahe an der Sonne vorbeigeht. Auf Grund seiner Allgemeinen Relativitätstheorie sagte Einstein 1916 einen Winkel von a = 1,8² voraus. Eine Messung im Jahre 1919 (von Eddington et al.) lieferte einen Wert von a = 2,0² ± 0,3². Dieses Ergebnis bestätigt mit hoher Wahrscheinlichkeit die Vorhersage und damit auch die Theorie. Ein Ergebnis von a = 0², wie es klassisch erwartet wird, liegt weit ausserhalb der ermittelten Fehlergrenzen (siehe Randspalte). Wäre der Fehler der Messung wesentlich grösser oder völlig unbekannt, könnte keine Entscheidung über die Gültigkeit von Einsteins Theorie getroffen werden.
Einstein wies 1916 darauf hin, dass nach der Allgemeinen Relativitätstheorie Licht, das nahe an der Sonne vorbeigeht, um einen Winkel a = 1,8¢ abgelenkt wird. Gemäss der vorrelativistischen Physik wird a = 0 erwartet, die Berücksichtigung der Speziellen Relativitätstheorie führt zur Vorhersage a = 0,9¢. Auch dieser Wert liegt ausserhalb der Fehlergrenzen der Messung von 1919.
2. Grundbegriffe
Systematischer und zufälliger Fehler
Systematische Fehler, herrührend von Unzulänglichkeiten der Messgeräte, verfälschen ein Messergebnis stets um den gleichen Betrag in die gleiche Richtung. Ihnen kommt man durch eine Wiederholung der Messung nicht auf die Spur, und sie können auch durch Rechenaufwand nicht verringert werden. Sie müssen auf andere Weise ermittelt und apparativ beseitigt werden.
Im Gegensatz dazu kann der statistische oder zufällige Fehler (zufällige Unsicherheit) das Ergebnis in beide Richtungen verändern. Er hat seine Ursache im Beobachter selbst. Er ist prinzipiell unvermeidbar, kann jedoch durch wiederholte Messungen und geeignete Auswertungsmethoden in seiner Grösse abgeschätzt werden.
Relativer und absoluter Fehler
Die Angabe der Messunsicherheit kann auf zwei verschiedene Weisen erfolgen:
Wird die Messunsicherheit als Zahlenwert dx (mit der gleichen Einheit wie die Messgrösse selbst) angegeben, dann spricht man vom absoluten Fehler.
Man kann die Qualität einer Messung aber auch durch den Quotienten aus dx und xBest anzeigen. Diesen Ausdruck bezeichnet man als relativen Fehler (relative Unsicherheit):
.
Diese dimensionslose Grösse gibt die Grösse der Messunsicherheit (nach Multiplikation mit 100) in Prozent an.
Signifikante Stellen und Fehlerangabe
Das Hauptanliegen der Fehlerrechnung ist es, nach praktischen Verfahren zu suchen, die es erlauben, eine quantitative Aussage über die Grösse der Messunsicherheit dx zu machen. Man muss sich jedoch darüber im klaren sein, dass es exakte Fehlerangaben nie geben kann. Was eine Fehlerrechnung mit ihren anerkannten Methoden leisten kann, sind Angaben darüber, mit welcher Wahrscheinlichkeit man bei einer identisch wiederholten Messreihe ein Ergebnis innerhalb bestimmter Grenzen erwarten kann.
Unter diesem Aspekt sollte man auch bei der Formulierung eines Messergebnisses zunächst nur die Stellen angeben, in denen sich der Fehler mit grosser Wahrscheinlichkeit noch nicht auswirkt (signifikante Stellen), plus eine weitere Stelle, die auf Grund der Fehlerrechnung unsicher ist. Da der Fehler selbst ebenfalls mit einer hohen Unsicherheit belastet ist, genügt dort im allgemeinen die Angabe einer, maximal zwei Stellen.
3. Messung einer Variablen
Um die Zuverlässigkeit einer Messung der Grösse x abschätzen zu können, führen wir sie mehrmals durch und unterziehen die so gewonnen Messdaten einer statistischen Analyse (statistische Unsicherheit).
Statistische Betrachtungen
Mittelwert
Es kann gezeigt werden, dass der (arithmetische) Mittelwert , der aus den Einzelwerten xi gewonnen werden kann, einen Bestwert xBest für die Messgrösse X darstellt:
.
Standardabweichung der Einzelmessung
Um einen Schätzwert für die mittlere Unsicherheit der Messwerte zu finden, bildet man die sogenannte Standardabweichung der Einzelmessung sx aus den einzelnen Werten und dem Mittelwert. Diese Grösse hängt nur von der Qualität der Messapparatur ab, nicht jedoch von der Anzahl der durchgeführten Messungen:
.
Standardabweichung des Mittelwertes
Naturgemäss hat man in den Mittelwert einer Messreihe ein grösseres Vertrauen als in die einzelnen Messwerte. Man verwendet daher die Standardabweichung für den Mittelwert als quantitatives Mass für die Messunsicherheit dx:
.
Ein Messergebnis für die Grösse x hat daher folgendes Aussehen:
.
Im folgenden soll versucht werden, zu begründen, dass der Mittelwert einer Messreihe als Bestwert für die gesuchte Grösse verwendet werden kann und dass die Standardabweichung des Mittelwertes eine Grösse darstellt, die eine quantitative Aussage über den Fehler ermöglicht.
Darstellung der Messergebnisse
Um dieses Ziel zu
erreichen, müssen statistische Verfahren in Anwendung kommen. Dazu ist es
erforderlich, die Daten einer umfangreichen Messreihe in passender Form
darzustellen. Eine einfache Möglichkeit bieten Stabdiagramme.
Stabdiagramme
Die Darstellung in
einem Stabdiagramm eignet sich besonders, wenn nur diskrete Ergebniswerte
auftreten (wie z.B. bei Würfelexperimenten oder anderen Zählexperimenten, bei
denen nur die Häufigkeit eines Ereignisses gefragt ist). Es wird die relative
Häufigkeit eines Ergebnisses gegen den Messwert als senkrechter Balken
aufgetragen ([10]Abb. 1).
Zunächst soll an einem
Würfelexperiment das Verfahren erläutert werden, da in diesem Fall die
Wahrscheinlichkeiten für das Eintreten der einzelnen Ergebnisse bekannt sind
und deshalb der Mittelwert einer unendlich langen Messreihe
(= wahrer Wert = Erwartungswert) berechnet werden kann.
Das Beispiel zeigt im linken Diagramm die beim Wurf mit zwei Würfeln bei N = 20 Würfen erzielten Augenzahlen. Die eingezeichnete Linie ist die berechnete Wahrscheinlichkeit. Sie ist gleich der bei unendlich vielen Versuchen erzielten Häufigkeitverteilung (= Grenzverteilung für die Einzelmessung).
Errechnet man Mittelwert und Standardabweichung für den Mittelwert, dann erhält man als Ergebnis für die dargestellte Messreihe(Messwert für x) = 7,05 ± 0,54.
Der wahre Wert X beträgt hier 7,0.
Der obere Teil von [11]Abb. 1 zeigt die Verteilung der
Mittelwerte, wenn man die Messreihe oft wiederholt. Würde man die gleiche
Messreihe unendlich oft durchführen, dann würden die Ergebnisse, nach ihrer
Häufigkeit sortiert, das Dreieck (die Grenzverteilung für den Mittelwert) füllen.
Das Flächenverhältnis des schraffierten Teils zur Gesamtfläche gibt also die
Wahrscheinlichkeit an, mit der eine erneut durchgeführte Messung innerhalb der
angegebenen Fehlergrenzen liegt, in unserem Fall sind das ca. 64,4 %. Damit
haben wir ein Verfahren kennengelernt, das eine quantitative Aussage bezüglich
des Fehlers erlaubt.
Voraussetzung dafür
ist jedoch, wie hier gezeigt wurde, die Kenntnis der Grenzverteilung. Wenn es
uns gelingt, für reale physikalische Messreihen die Grenzverteilung mathematisch
zu formulieren, dann haben wir unser Ziel erreicht.
Histogramm
In den meisten Fällen
liefert eine Messung keine ganzzahligen Ergebnisse, da die meisten
physikalischen Grössen einen kontinuierlichen Bereich möglicher Werte haben. Man
teilt dann den Wertebereich in eine geeignete Anzahl von Intervallen oder
Klassen ein und zählt jeweils, wieviele Ergebniswerte in eine solche Klasse
fallen (Histogramm). Als Beispiel wurden in [12]Abb. 2 die Messungen einer Zeit von
ca. 2,67 s (Messgenauigkeit 0,001 s, Klassenbreite 0,01 s) dargestellt. Man
erkennt qualitativ, dass die zu erwartende Verteilung bei einer Steigerung der
Anzahl der Messungen durch eine symmetrische Glockenkurve wiedergegeben wird,
wie sie in der Abbildung bereits andeutungsweise eingetragen ist.
Grenzverteilungen
Die Verteilungskurve der Messresultate für den Grenzfall unendlich vieler Messungen nennt man die Grenzverteilung dieser Messung.
Wenn die Grenzverteilung f(x) explizit bekannt ist, dann kann daraus der Mittelwert und die Standardabweichung errechnet werden:
Verteilungen
Wir stehen nun vor der
Frage, ob es möglich ist, die Grenzverteilung für ein bestimmtes Experiment
vorauszusagen. Man kann zeigen, dass in den meisten Fällen als Grenzverteilung
die sogenannte Normalverteilung (Gauss-Verteilung, normale Dichtefunktion)
angenommen werden kann. Zu Erklärung dieses Zusammenhanges geht man von der
sog. Binomialverteilung für die Ereignisse aus.
Binomialverteilung
Diese Verteilung ist anwendbar, wenn mit vielen identischen Objekten das gleiche Experiment durchgeführt wird, wobei für jedes Objekt ein bestimmtes Ergebnis mit der Wahrscheinlichkeit p möglich ist. Wird mit n Teilchen das gleiche Experiment gemacht, dann ist die Wahrscheinlichkeit dafür, dass bei n Teilchen das Ereignis beobachtet wird,
In [13]Abb. 3 werden die Verteilungen für die
folgenden Experimente dargestellt:
· Wahrscheinlichkeit, beim Werfen von drei Würfeln eine bestimmte Anzahl
von Einsen zu erhalten (Mittelwert = 1/2)
· Wahrscheinlichkeit, beim Werfen von zwölf Würfeln eine bestimmte Anzahl
von Einsen zu erhalten (Mittelwert = 2)
· Wahrscheinlichkeit, beim Werfen von zwölf Würfeln eine bestimmte Anzahl
gerader Augen zu erhalten (Mittelwert = 6).
Man erkennt, dass mit
steigendem Mittelwert auch diese Verteilung die Form einer symmetrischen
Glockenkurve annimmt. Es kann gezeigt werden, dass für diesen Grenzfall die
Binomialverteilung in die sogenannte Gauss-Verteilung oder Normalverteilung fX,s(x) übergeht.
Poisson-Verteilung
Auch die
Poisson-Verteilung kann für den Fall grosser Objektzahlen durch die
Normalverteilung fX,s(x) beschrieben werden.
Normal- oder Gauss-Verteilung
Bei dieser Funktion handelt es sich um eine Glockenkurve, die durch zwei Parameter charakterisiert ist: Sie ist beim Wert X (dem wahren Wert) zentriert und besitzt am Wendepunkt die Breite 2s (Breitenparameter).
Sie hat das in [14]Abb. 4 dargestellte Aussehen und
gehorcht der folgenden Funktion:
Wenn es uns gelingt,
zu zeigen, dass die Werte einer Messreihe, die unabhängig und zufällig sind,
durch die Binomialverteilung gegeben sind, dann haben wir unser Ziel erreicht.
Die Normalverteilung als Grenzverteilung bei Messreihen
Unter der Annahme, dass bei der Messung einer Grösse x, deren wahrer Wert X sei, n unabhängige Quellen zufälliger Abweichungen auftreten (unabhängige Unsicherheit), die der Einfachheit halber alle gleich gross sein sollen und mit gleicher Wahrscheinlichkeit den Messwert vergrössern bzw. verkleinern sollen, dann lässt sich zeigen, dass die zu erwartenden Wahrscheinlichkeiten für die einzelnen Messwerte durch die Binomialverteilung beschrieben werden (Random-Walk-Problem!), welche für grosses n durch die Normalverteilung ersetzt werden kann. Damit erhalten wir die Möglichkeit, eine quantitative Aussage darüber zu machen, was bei dieser Verteilung die Angabe der Unsicherheitsgrenze s bedeutet.
Wertet man das Integral
aus, dann sieht man, dass ca. 68 % aller Messungen (dies entspricht wiederum der gerasterten Fläche in der Abbildung) im Bereich dieser Unsicherheitsgrenzen liegen.
Fehlerfunktion
Man kann das Vertrauen, das in ein Messergebnis gesetzt wird, dadurch vergrössern, dass man den möglichen Fehlerbereich auf den Wert t × s erweitert. Mit welcher Wahrscheinlichkeit in diesem Fall eine erneute Messung innerhalb der Fehlergrenzen liegt, kann aus der sogenannten Gaussschen Fehlerfunktion (auch normales Fehlerintegral genannt) abgelesen werden.
Die Integralfunktion ([15]Abb. 5) zeigt die Wahrscheinlichkeit P, dass ein Ergebniswert von x
innerhalb von t Standardabweichungen vom wahren
Wert X fällt. Lässt man eine Unsicherheit von 2s nach jeder Seite zu, dann liegen
bereits ca. 95 % aller Messungen im Fehlerbereich.
Das Verwerfen von Daten
Mit Hilfe des Chauvenetschen Kriteriums kann beurteilt werden, ob ein etwas ausgefallener Wert innerhalb einer Messreihe (ein sogenannter »Ausreisser«) bei der Mittelwertbildung berücksichtigt werden sollte, oder ob der Wert aus einem Experimentierfehler resultiert und deshalb verworfen werden muss.
Wir wollen annehmen, dass eine Messreihe aus N Messungen einen Mittelwert von und eine Standardabweichung von sx besitze. Wir wollen weiter annehmen, dass unter den Messwerten ein verdächtiger Wert xverd ist, der um (tverd × sx) vom Mittelwert abweicht. Mit Hilfe der Integralfunktion kann man die Wahrscheinlichkeit P ausrechnen, mit der ein Messwert ausserhalb dieser Schranken fällt. Multipliziert man dieses P mit N, dann erhält man die Anzahl der Messwerte, die im Mittel auf Grund der Normalverteilung ausserhalb (tverd × sx) fallen. Damit erhalten wir die erwartete Anzahl n von Messwerten, die mindestens so schlecht wie xverd sind:n(schlechter als xverd) = N P (ausserhalb tverd × sx).
Wenn n kleiner als 1 / 2 ist, dann erfüllt xverd das Chauvenetsche Kriterium nicht und wird verworfen. Auch dieses Kriterium ist wie alle anderen Aussagen der Fehlerrechnung nur eine Wahrscheinlichkeitsangabe und damit in ihrer Wertung einer subjektiven Beurteilung unterworfen.
Mittelwert als Bestwert
Es soll nun noch begründet werden, dass der Mittelwert einer Messreihe tatsächlich als Bestwert für die gesuchte Grösse interpretiert werden kann.
Die wahren Werte X und s (aus einer unendlich langen Messreihe ermittelt!) sind nicht bekannt. Um aus endlich vielen Daten einen Bestwert für diese Grössen zu erhalten, wird das Prinzip der grössten Wahrscheinlichkeit angewandt.
Wären die Parameter X und s bekannt, dann könnten die Wahrscheinlichkeiten für die tatsächlich gemessenen Werte xi berechnet werden. So ist z.B. die Wahrscheinlichkeit, den Wert x1 zu messen, auf Grund der Normalverteilung proportional zum Ausdruck
.
Die Wahrscheinlichkeit, alle xi der Messreihe zu erhalten, ist das Produkt der Einzelwahrscheinlichkeiten:
In dieser Beziehung sind X und s unbekannt. Als Bestwerte ermitteln wir diejenigen Werte dieser Grössen, für welche die beobachteten x1, x2, 1/4, xN am wahrscheinlichsten sind. P (als Funktion von X) ist maximal, wenn der Exponent minimal ist. Differenziert man diesen und setzt die Ableitung gleich null, dann erhält man
Der so definierte Bestwert X ist gleich dem Mittelwert der Messreihe. Nach dem gleichen Verfahren ergibt sich, dass der Bestwert für die Breite s gleich der Standardabweichung der N beobachteten Werte xi ist.
Mit anderen Worten:
Für eine Normalverteilung, die am Mittelwert zentriert ist und die Breite s
besitzt, ist die Wahrscheinlichkeit am grössten, die real gemessene
Ergebnisverteilung zu erhalten.
Der gewichtete Mittelwert
Oft ergibt sich die Aufgabe, mehrere unabhängige Messungen derselben physikalischen Grösse x1, x2,1/4xN zu einem Bestwert xBest zu kombinieren, wobei die Messungen mit unterschiedlicher Genauigkeit s1, s2, 1/4, sN durchgeführt wurden. Auch hier hilft uns das Prinzip der grössten Wahrscheinlichkeit weiter.
Der Bestwert für den unbekannten Wert X ist derjenige Wert, für den die tatsächlichen Beobachtungen xA und xB am wahrscheinlichsten sind. Im Exponenten der e-Funktion erscheint diesmal ein Term der Form
Wird differenziert und nach X aufgelöst, erhält man den folgenden gewichteten Mittelwert als Bestwert
,
wobei die als Gewichte definierten Grössen benutzt wurden: Kleine Standardabweichung bedeutet grosses Gewicht bei der Mittelung.
Der Chi-Quadrat-Test
Um zu testen, ob die Ergebnisse einer Messreihe der zu erwartenden Grenzverteilung folgen, kann man den sogenannten Chi-Quadrat-Test oder c2-Test durchführen.
Wir wollen annehmen, dass eine Grösse x mehrmals gemessen wird, und es soll geprüft werden, ob die Werte einer bestimmten Verteilung f(x) folgen. Dazu teilen wir die Messwerte in n Klassen ein (k = 1, ..., n) und ermitteln jeweils die Anzahl Bk der Beobachtungen, die in Klasse k fallen. Diese Zahlen vergleichen wir mit der auf Grund der als bekannt angenommenen Verteilung errechneten Anzahl von erwarteten Messwerten Ek. Die damit gebildete Grösse
ist ein quantitatives Mass dafür, ob die beobachteten Messwerte mit der angenommenen Verteilung beschrieben werden können.
Bei c2 = 0 wäre die Übereinstimmung vollkommen. Im allgemeinen sollten die einzelnen Terme der Summe etwa 1 sein, da im Mittel die Abweichung des Messwertes vom Idealwert in der Grössenordnung der Standardabweichung liegen sollte. Wenn die angenommene Verteilung die Messungen richtig beschreibt, sollte c2 @ n oder kleiner sein, da die Summe n Terme umfasst. Ist dagegen c 2 viel grösser als n, dann liegt die Vermutung nahe, dass die Messwerte nicht der erwarteten Verteilung folgen.
4. Fehlerfortpflanzung
Funktionen mehrerer Variabler
Im allgemeinen Fall beruht die Bestimmung einer unbekannten Grösse q auf der Messung mehrerer Variabler x, y, usw. Unter der Annahme, dass die Fehler der einzelnen Variablen unabhängig und normalverteilt sind, erhält man die Unsicherheit für q (Fehlerfortpflanzung) aus der Beziehung
.
Kovarianz in der Fehlerfortpflanzung
Um festzustellen, ob die Fehler zweier Messgrössen x und y tatsächlich unabhängig sind, bildet man die Kovarianz. Darunter versteht man einen Ausdruck der Form
.
Bei einer Abhängigkeit (z.B. zu grosses x ergibt stets ein zu grosses y) haben die Klammern stets das gleiche Vorzeichen, und die Varianz ist gross. Bei unabhängigen Messwerten sollte man erwarten, dass sich die Kovarianz nach vielen Messung dem Wert null nähert.
Lineare Regression (Methode der kleinsten Quadrate)
Mit dieser Methode wird die Gerade y = A + Bx (d.h. die Konstanten A und B) bestimmt, die am besten den Zusammenhang zwischen zwei Variablen x und y wiedergibt, von denen angenommen wird, dass zwischen ihnen ein linearer Zusammenhang besteht (Methode der kleinsten Quadrate, lineare Regression).
Auch hier geht man wieder von der Wahrscheinlichkeit aus, die beobachteten Wertepaare (x, y) zu erhalten, und berechnet die Grössen A und B, für die die Wahrscheinlichkeiten maximal sind.
Unter der Annahme, dass nur die y-Werte unsicher sind und diese Werte um den wahren Wert von y mit dem Breitenparameter sy normalverteilt sind, sind die Bestwerte für A und B gegeben durch
Die Abkürzung D bedeutet
.
Diese Beziehungen liefern die Bestwerte für A und B auf der Grundlage der gemessenen Punkte (xi, yi), ..., (xN, yN).
Wenn nach der Unsicherheit dieser Grössen gefragt wird, muss erst etwas über die Unsicherheit der Messwerte von yi gesagt werden. Die yi sind nicht Messwerte derselben Grösse, sondern sie sind mit den (als fehlerfrei angenommenen) xi-Werten durch die Geradengleichung A + Bxi verknüpft. Also sind die Abweichungen normalverteilt und alle mit derselben Breite sy beim Wert 0 zentriert. Auch hier kann das Prinzip der grössten Wahrscheinlichkeit angewendet werden. Es liefert als besten Schätzwert für sy das Resultat
Es darf hier nicht durch die Anzahl der Wertepaare N dividiert werden, sondern durch die Anzahl der Freiheitsgrade. Da die Wertepaare bereits benutzt wurden, um die Konstanten A und B zu berechnen, sind nur noch N - 2 dieser Wertepaare voneinander unabhängig und dürfen für die Berechnung verwendet werden. Für die Unsicherheiten von A und B ergeben sich damit die Beziehungen:
und
Nach der Methode der kleinsten Quadrate lassen sich Messwertepaare auch an andere Beziehungen (z.B. Polynome, Exponentialfunktion usw.) anpassen.
Linearer Korrelationskoeffizient
Von der linearen Regression zu unterscheiden ist eine Fragestellung, bei der untersucht werden soll, ob zwischen zwei Messgrössen ein z.B. linearer Zusammenhang (Korrelation) besteht. So könnte man z.B. daran interessiert sein, herauszufinden, ob Studenten, die in den Übungen hohe Punktzahlen, d.h. gute Ergebnisse erreichen, auch in der Abschlussprüfung gut abschneiden.
Dazu muss geprüft werden, wie gut eine Menge von Messwertepaaren (xi, yi), ..., (xN, yN) einer linearen Beziehung gehorcht. Dazu muss der lineare Korrelationskoeffizient gebildet werden. Dieser ist definiert zu
.R kann zwischen +1 und -1 liegen. Positive Werte wären das erwartete Ergebnis, negative Werte dagegen würden bedeuten, dass gute Übungsergebnisse zu schlechten Abschlussprüfungen führen. Für diese Werte liegen die Punkte dicht bei einer Geraden. Für r = 0 besteht keine Korrelation zwischen den x- und y-Werten.
Literatur:
John R. Taylor:
Fehleranalyse, VCH Verlagsgesellschaft, Weinheim 1988;
G.L. Squires: Messergebnisse und ihre Auswertung, de Gruyter, Berlin, 1971.
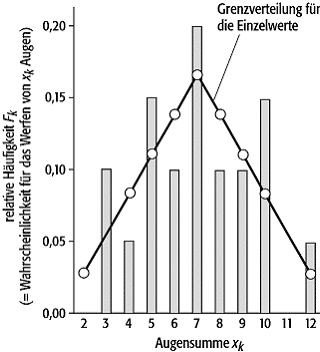
Fehlerrechnung 1: Die obere Teilabbildung zeigt in Form eines Stabdiagramms die relative Häufigkeit, mit der beim 20maligen Werfen von zwei Würfeln eine bestimmte Augensumme erzielt wurde. Die für dieses Experiment leicht zu berechnenden Wahrscheinlichkeiten (= Ergebnis bei unendlich vielen Würfen = Grenzverteilung) sind ebenfalls eingetragen. Unten sieht man die Grenzverteilung für die Mittelwerte, die aus jeder Messreihe errechnet werden können. Sie ist, wie erwartet, bedeutend schmaler: Die Mittelwerte streuen weniger als die Einzelmessungen (Abszissenwerte beachten!).
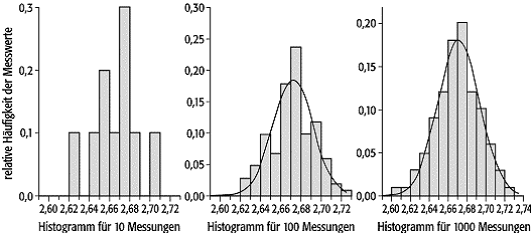
Fehlerrechnung 2: So ändert sich die Verteilung der Messwerte in einem realen physikalischen Messprozess, wenn man die Anzahl der Messungen erhöht. Die Verteilung wird glatter, ist symmetrisch und hat die Form einer Glockenkurve. Dies ist die gesuchte Grenzverteilung für das Experiment.
Fehlerrechnung 3: Drei Beispiele für Experimente, die mit Hilfe der Binomialverteilung mathematisch korrekt beschrieben werden können. Auch hier wird mit steigendem Mittelwert für die Verteilung eine symmetrische Glockenkurve beobachtet.
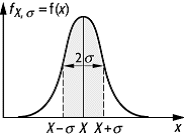
Fehlerrechnung 4: Es kann mathematisch exakt gezeigt werden, dass sowohl die Binomial- als auch die Poisson-Verteilung für grosse Mittelwerte in die sogenannte Gauss- oder Normalverteilung übergeht. Sie ist charakterisiert durch den Wert X und die Breite 2s. Diese beiden Grössen entsprechen den Begriffen Bestwert und Unsicherheit der Messung.
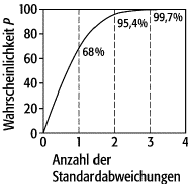
bottom:.0001pt\'>Fehlerrechnung 5: Wahrscheinlichkeit, mit der der Mittelwert einer neuen Messreihe innerhalb der Fehlergrenzen liegt, wenn als Fehlergrenze mehr als eine Standardabweichung angegeben wird. Man erkennt, dass eine Verdreifachung des Fehlerbereichs bereits eine fast hundertprozentige Sicherheit bedeutet, mit einem neuen Ergebnis innerhalb dieser Grenzen zu liegen.
Techniklexikon.net
Das freie Technik-Lexikon. Fundierte Informationen zu allen Fachgebieten der Ingenieurwissenschaften, für Wissenschaftler, Studenten, Praktiker & alle Interessierten. Professionell dargeboten und kostenlos zugängig.
Techniklexikon
Modernes Studium der Physik sollte allen zugängig gemacht werden.